
Blog Summary
Every AI consulting company sounds the same in a pitch deck. The real gaps show up in discovery calls. This guide gives you 7 questions, follow-up probes, a scoring framework, and a red-flag checklist to separate builders from demo-ware shops.
Your shortlist looks the same on paper. Every AI consulting company claims deep ML expertise. Every one cites Fortune 500 logos. Every one promises fast, measurable outcomes.
The real differences only surface in discovery calls. And only if you ask the right questions.
Most tech leaders walk into vendor evaluations with a generic question list, often without a clear picture of what AI consulting actually involves in 2026. Polished firms have prepared answers for all of them. That is why your evaluation feels inconclusive. You leave with impressions, not evidence.
This guide fixes that. It gives you seven questions designed to expose real capability gaps. Each one includes the answer patterns you want to hear. It also flags the patterns that should raise concern. Follow-up probes help you cut through rehearsed pitches. At the end, you get a scoring framework for side-by-side comparison.
Use this before you sign a contract. Not after.
Why the Wrong AI Consulting Company Costs More Than You Think
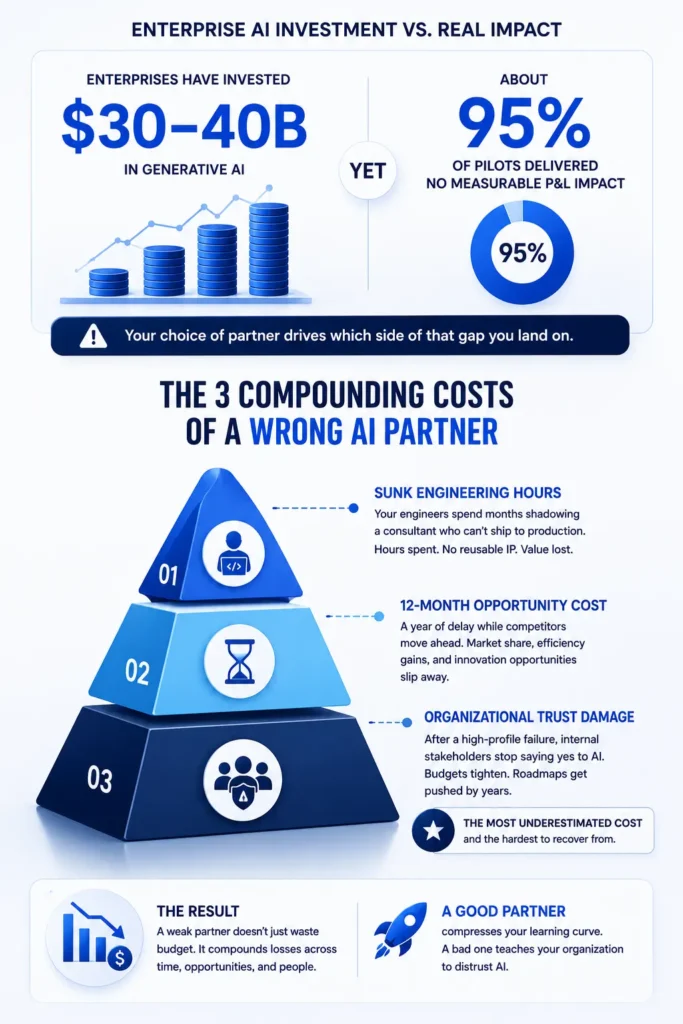
AI project failure rates are not improving with time. MIT’s Project NANDA study in 2025 delivered a sobering finding. Enterprises have invested roughly $30 to $40 billion in generative AI. Yet about 95% of pilots delivered no measurable P&L impact. The gap between spend and value is wider than most boards realize.
Your choice of partner drives which side of that gap you land on.
A weak consulting engagement compounds three costs. First, sunk engineering hours shadowing a consultant who cannot ship to production. Second, opportunity cost of a 12-month delay while competitors move ahead. Third, organizational trust damage when a high-profile AI project underdelivers.
The third cost is the one tech leaders underestimate. After a failed flagship project, internal stakeholders stop saying yes to AI proposals. Budget approvals tighten. Your roadmap gets pushed by years.
A good partner compresses your learning curve. A bad one teaches your organization to distrust AI. If you are still scoping what AI consulting should and should not cover, that question deserves its own evaluation step before you shortlist vendors.
That asymmetry is why the seven questions matter more than the price.
How to Use These 7 Questions in Your Vendor Evaluation
Discovery Call Checklist
- Block 60 to 90 minutes per call
- Bring one technical lead and one business stakeholder
- Ask the main question, then every follow-up probe
- Score within 24 hours, not at the end
- Skip the demo. Save it for later.
Run the same seven questions across every shortlisted AI consulting company. Take notes on the specific language each firm uses. Note what they volunteer and what they avoid.
Every vendor has prepared answers for the main question. Follow-up probes expose whether the main answer was genuine or rehearsed. Ask the probes every time.
Allocate 60 to 90 minutes per discovery call. Resist the urge to accept demos or case study walkthroughs as answers. You can review those materials later.
Bring one technical leader and one business stakeholder to each call. The technical person catches hand-waving in the model and infrastructure answers. The business person catches vague governance and ROI claims.
Score after each call, not at the end. Patterns fade from memory within 48 hours. The scoring framework at the bottom of this guide gives you a structure.
Question 1: Can You Show Me Three Production AI Systems You Built That Are Still Running Today?
Why this matters. Every AI consulting firm has impressive pitch decks. Far fewer have solutions running in production 18 months later. This question separates builders from demo-ware shops.
Production survival is the real signal of capability. It tests whether the firm can handle the unglamorous work that follows launch. Think monitoring, drift correction, incident response, and integration debt.
What a strong answer sounds like. Specific client names, or anonymized descriptions with clear sector and company size. Deployment year. What is still running today. Measurable outcomes. Honest descriptions of what was hard or what they would do differently.
Strong firms will mention at least one project that needed re-architecting after launch. That admission signals operational maturity.
What a weak answer sounds like. Vague case studies with no deployment dates. Heavy emphasis on pilots and POCs rather than production systems. Inability to name a single system currently running. Reliance on logo slides as evidence.
Watch for firms that pivot to talking about “transformation engagements” instead of shipped systems. That phrasing usually means strategy decks, not working software.
Follow-up probes:
- Of those three systems, which was hardest to keep running and why?
- Can you connect me with the technical lead on the client side for one reference?
The second probe is the real test. Firms with real production wins have reference clients who will take a call.
Question 2: Who Will Actually Work on My Project, and What Are Their Backgrounds?
Why this matters. The bait-and-switch problem runs deep in consulting. Senior staff pitch. Junior staff deliver. This pattern is common across every consulting vertical and especially damaging in AI.
AI work requires genuine technical depth. A senior ML engineer ships production systems. A generalist with a few prompt engineering courses does not. Substitution destroys outcomes.
What a strong answer sounds like. Named team members before contract signing. LinkedIn profiles shared proactively. Engineers with relevant publications, open-source contributions, or production ML experience. Clear escalation paths when senior input is needed.
Strong firms will tell you exactly how many hours each named person will commit. They will also describe their bench depth honestly.
What a weak answer sounds like. “Our senior team oversees all projects.” Unnamed resources behind vague role titles. Heavy offshore delivery without transparency about who leads the technical work. Discomfort with sharing specific CVs before contract.
A firm unwilling to name the team before signing is optimizing for staffing flexibility. Not for your outcomes.
Follow-up probes:
- What percentage of delivery hours will come from the team you just named?
- What is your policy if a named team member leaves mid-engagement?
The second probe matters. Teams lose people. You want to know what happens when they do.
Question 3: How Do You Decide Between Building, Fine-Tuning, and Using Off-the-Shelf Models?
Why this matters. This is the vendor neutrality test. A firm that always recommends custom development has a business model problem. Not a recommendation. Same with a firm that always recommends a specific cloud provider.
Most AI problems in 2026 do not require custom model training. The best AI consulting 2026 partners help you avoid unnecessary complexity. They know that shipping something simple and measurable beats building something ambitious and stalled.
What a strong answer sounds like. A clear decision framework. Starts with the cheapest option that meets requirements. Discusses total cost of ownership, not just build cost. References specific projects where they recommended against custom development.
Strong firms will describe clear evaluation criteria for each option. That includes retrieval augmented generation, fine-tuning, and prompt engineering. They will also discuss when a non-AI solution fits better.
What a weak answer sounds like. Defaults to “it depends” without a framework. Cannot name a situation where off-the-shelf was the right answer. Pushes proprietary platforms as the foundation for every recommendation.
Watch for firms whose answer always maps to their highest-margin service line. That is not advice. That is sales.
Follow-up probes:
- When was the last time you recommended a client not build custom, and why?
- How do you handle cases where the client wants custom but the data does not support it?
The second probe tests willingness to push back on misguided client enthusiasm. Firms that push back are worth more than firms that just take the check.
Question 4: What Does Your Engagement Look Like If My Data Is a Mess?
Stat to Remember
Data completeness, quality, and readiness is the single biggest barrier between GenAI pilots and production deployment (Informatica CDO Insights 2025). Any firm that expects clean data on day one cannot help you with the hardest part of the project.
Why this matters. Most organizations have data quality problems. Consulting firms that skip past this in pitches will stumble in delivery.
Informatica’s CDO Insights 2025 survey surfaced the scale of this problem. 43% of technology leaders cite data completeness, quality, and readiness as their top obstacle. That obstacle is what blocks GenAI initiatives from moving to production. A firm that underestimates data work will miss every timeline it sets.
What a strong answer sounds like. Honest about discovery and assessment phases. Describes how they handled data quality issues in past projects. Has patterns for incremental data remediation without boiling the ocean.
Strong firms build data readiness checkpoints into their engagement plan. They scope data work as a first-class deliverable, not an afterthought.
What a weak answer sounds like. Assumes clean, well-structured data from day one. Promises fast timelines without addressing readiness. Treats data preparation as “out of scope.” Or treats it as your problem to solve first.
Any firm that expects clean data before arriving is telling you something important. They cannot help you with the hardest part of the project.
Follow-up probes:
- Can you walk me through a project where data issues forced you to change approach mid-engagement?
- How do you price and scope data preparation work?
The pricing probe is revealing. Firms with mature data capabilities have clear pricing. Firms without them quote vague ranges.
Question 5: How Do You Handle Model Governance, Monitoring, and Drift After Launch?
Why this matters. Many AI consulting firms build and walk away. The regulatory picture in 2026 leaves no room for this gap. The EU AI Act’s general-purpose AI rules are now in force. US state-level regulation is expanding. Post-launch governance is no longer optional.
Models degrade over time. Compliance obligations run for the life of the system. Firms without post-launch capability deliver short-lived solutions and long-tail regulatory risk.
What a strong answer sounds like. Direct references to MLOps practices, monitoring dashboards, drift detection, retraining schedules, and governance documentation. Familiarity with the NIST AI Risk Management Framework or equivalent standards.
Strong firms distinguish between technical monitoring and compliance monitoring. They can describe both with equal confidence.
What a weak answer sounds like. Treats governance as an afterthought or a bolt-on service. Offers post-launch support only as an expensive retainer. Cannot discuss drift detection specifics beyond the phrase itself.
A firm that builds without governance hands you future audit risk. Every deployment adds to that pile.
Follow-up probes:
- Who on your team owns MLOps versus model development?
- How have you helped clients respond to regulatory audits of deployed models?
The second probe is rarely answered well. Firms with real production governance experience have war stories. Firms without it change the subject.
Question 6: What Will My Team Be Able to Do on Their Own After This Engagement?
Why this matters. The capability transfer question separates partners from vendors. Firms that build dependency treat you as a long-term revenue line. Firms that build your team treat you as a success story to reference.
Your goal is a stronger organization, not a permanent consulting invoice. Every engagement should leave your team measurably more capable than when it started.
What a strong answer sounds like. Explicit knowledge transfer plans. Pair programming with internal engineers. Runbooks and documentation as deliverables. Scheduled handoff milestones. Clear skill-building targets for internal champions.
Strong firms are comfortable pointing clients toward graduation. They measure success by what you can do without them. Not by how long you keep paying them.
What a weak answer sounds like. “We will document everything” with no specifics. Heavy retainer push before the initial engagement even starts. Unclear handoff criteria. Resistance to defining what “done” looks like.
A clear endpoint should be visible from day one. Without it, you are not looking at a project. You are looking at a subscription.
Follow-up probes:
- Which previous client has graduated from your services entirely, and how did that handoff work?
- What skills would you expect my team to have 12 months after this engagement?
The first probe cuts through marketing language. A firm that cannot name a single graduated client does not do graduations.
Question 7: What Would You Tell Me Not to Do, and When Would You Walk Away From This Project?
Why this matters. This is the trust question. A consulting firm willing to push back is a partner. A firm that agrees with everything is a vendor chasing a deal.
Some AI projects should not happen. Others should happen later. Others should happen differently than the client initially imagined. A firm willing to say so protects you from expensive mistakes.
What a strong answer sounds like. Specific examples of scoping back, recommending against features, or declining engagements entirely. Clear criteria for when they walk away from a deal. Confidence in having those conversations with executives.
Strong firms describe an engagement they turned down recently and explain why. That specificity is hard to fake.
What a weak answer sounds like. “We work with you to align on goals.” They cannot name a time they pushed back. Cannot name a type of engagement they decline. Treats every request as a fit.
A firm that has never walked away from a deal has no standards. That is a problem you will discover later, not earlier.
Follow-up probes:
- What is the most recent engagement you turned down and why?
- What would make you recommend we not proceed with the scope we have discussed?
The second probe is the one where many firms hesitate. The hesitation itself is your signal.
Scoring Your AI Consulting Services Shortlist
A structured scorecard beats gut feel. Score each firm from 1 to 5 on each of the seven questions. A 1 means evasive or generic answer. A 5 means specific, credible, confidence-building answer.
Weight the questions based on your context. An early-stage AI program should weight Questions 1, 2, and 6 most heavily. When building from scratch, three things matter most. Production capability, team quality, and capability transfer.
A regulated industry should weight Questions 5 and 7 most heavily. Governance depth protects you from compliance failures. Willingness to push back prevents scope creep into risky territory.
A tight timeline should weight Questions 2 and 4 most heavily. Team quality and data readiness determine whether your deadline is realistic.
Add a simple culture fit column alongside the scores. Rate how comfortable you would be escalating a problem to each firm. Communication clarity matters as much as technical depth once the engagement starts.
Score each firm within 24 hours of the discovery call. Patterns fade fast. The scorecard is a structured aid, not a replacement for judgment. When scores are close, the tie-breaker is almost always culture fit. Look at how well their communication style matches your team’s.
Red Flags That Override Any Good Score
Even a high-scoring firm can have disqualifiers. Use this list as an override layer.
- Guaranteed ROI numbers before any data review. Nobody can promise specific returns without seeing your data. Anyone who tries is selling, not advising.
- Pressure to sign before you finish evaluating other vendors. Urgency tactics reveal that the firm does not expect to win on merit.
- Inability to explain technical choices in plain language. Jargon is a substitute for clarity, and clarity is how real experts communicate.
- No references from organizations of similar size or complexity. Experience with small startups does not transfer to enterprise integration. The reverse is also true.
- Exclusive partnerships that force tool or cloud lock-in. Bias in recommendations shows up months later as an unreasonable switching cost.
- Pitches that skip the assessment phase entirely. A firm that jumps straight to building is a firm that will build the wrong thing.
- No clear stance on compliance or governance. In 2026, that is malpractice.
Any one of these flags should trigger a deeper review. Two or more, and the firm is off the shortlist regardless of their scores.
What the Top AI Consulting Firms Are Doing Differently in 2026
The top AI consulting firms this year look different from three years ago. The work has moved up the stack.
First, the center of gravity has shifted from model building to agentic system design. Top firms now architect multi-step workflows. Models coordinate with tools, APIs, and other models. The hard problem is no longer training. It is orchestration, state management, and error handling across chains of decisions.
Second, the emphasis has moved from building custom LLMs to evaluation and orchestration frameworks. Evaluation infrastructure, which measures output quality continuously in production, has become the real differentiator. Firms without strong eval practices ship unreliable systems and do not know it.
Third, the business model is shifting from project delivery to continuous AI product operations. The best firms now run long-term partnerships. They focus on adapting, measuring, and improving AI systems in production. The underlying models keep changing. The business context keeps changing. The partnership has to keep pace with both.
The BCG AI Radar 2026 study confirmed this pattern. Only a small subset of companies are capturing meaningful value from AI investments. Those companies share one pattern. They treat AI as a product capability, not a project deliverable. The consulting firms that can support that mindset are pulling away from the rest.
At Ecosmob, our AI solutions practice reflects these shifts. We focus on agentic architectures, evaluation infrastructure, and capability transfer. Not one-off builds. TelephonyNest exists to share what we learn along the way.
Key Takeaways
Shortlists of AI consulting companies look identical on paper. The seven questions in this guide expose the differences that paper cannot show.
Ask every firm the same questions. Use the follow-up probes every time. Score within 24 hours of each call. Apply the red flags as an override layer. The firm that emerges from this process has earned your contract. Not the firm that pitched the best.
The cost of this level of evaluation is a few extra hours per vendor. The cost of skipping it is usually a six or seven-figure mistake. That mistake sets your AI program back by a year.
If you would like to talk through your evaluation, we are happy to help. Our team works in this space every day. Reach out to our team at Ecosmob. No pitch. Just a clear conversation about what makes sense for your situation.
Final Take-Away
Spend the hours.
The cost of running these 7 questions is a few extra hours per vendor. The cost of skipping them is usually a six or seven-figure mistake that sets your AI program back a year.
FAQs
How many AI consulting companies should I shortlist before running these questions?
Three to five is the practical range. Fewer than three, and you lose pricing leverage and comparison signal. More than five, and evaluation fatigue starts distorting your judgment.
How do I evaluate boutique firms against Big 4 consultancies?
Use the same seven questions. Big 4 firms often win on brand recognition but staff projects with junior generalists. Boutiques often have senior engineers on every engagement but shallow bench depth. The questions surface both realities quickly.
What if a vendor refuses to answer some of these questions?
That is data. Firms with strong answers volunteer them. Firms without strong answers deflect. Treat refusal as a low score on that dimension and move on.
How much should I share about my budget during evaluation?
Share a range, not a number. Firms that match scope to your exact budget are optimizing for your wallet. Not for your outcomes. Firms that propose scope first and discuss budget second are usually the better partners.